
Beyond LoRA: Hugging Face Tests Better Fine-Tuning Methods
Hugging Face benchmarked LoRA against newer PEFT methods like OFT, which beat it on image generation while using less memory. The default is not always the best fit.
Hugging Face benchmarked LoRA against newer PEFT methods like OFT, which beat it on image generation while using less memory. The default is not always the best fit.

Midjourney added a Draft Mode to V8.1 that generates 24 low-resolution images for about half the fast-hour cost of a standard job.

Hammermind launched on Hacker News as a single-prompt asset pipeline for game developers, turning a text description into game-ready pixel art and audio.

Shutterstock turned its stock content library into a human-led, AI-powered creative platform on June 11, 2026, letting creators generate, edit, and customize assets in one workflow with commercial licensing carried through to AI output.

Krea added Generative Sliders, four live controls that shape intensity, complexity, movement, and prompt creativity before an image renders.

xAI added file storage, public URLs, and a Files-to-Imagine pipeline to the Grok Imagine API on June 10, 2026, removing the upload-download shuffle from automated image and video edits.

Apple WWDC 2026 unveiled five new Foundation Models, a rebuilt Siri AI, Image Playground, and Spatial Reframing, built with Google Gemini collaboration.

ComfyUI v0.24.1 ships Krea 2 Medium Turbo model support, two Bria video background nodes, a Seedance 2.0 1080p artifact fix, and seed control for Flux Erase.

Black Forest Labs ships FLUX.2 klein 4B preloaded on ASUS ProArt RTX laptops with sub-5s offline image generation on 8GB VRAM.
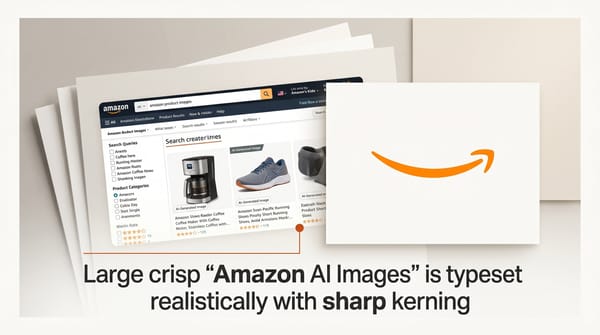
Amazon will display AI-generated product images in shopping search results, showing visual hints below autocomplete suggestions for queries like cowl neck or rattan.

Reve 2.0 generates 4K images using code-based layout controls, giving designers precise composition without prompt engineering.

Ideogram released its first open-weight text-to-image model on June 3, 2026: a 9.3B parameter Diffusion Transformer with JSON-structured prompting, in-image text rendering, and day-zero ComfyUI support.

Microsoft used its Build 2026 keynote on June 2 to ship a refreshed MAI media stack: MAI-Image-2.5 with editing, MAI-Voice-2 for TTS, and MAI-Transcribe-1.5 for ASR.

Fizgig v1.2.4 makes full Flux 2 Klein 9B LoRA training possible on 16GB GPUs using fp8 Base DiT at 9.6GB VRAM. The free, open-source studio includes training presets, repair tools, and profiler.

NVIDIA pushed new PiD checkpoints June 2 with a FLUX.2 color-fix variant plus Qwen-Image support, all on Apache 2.0 for direct 4K decode in ComfyUI.

Microsoft shipped three creator-focused AI models on June 2: MAI-Image-2.5 beats Gemini on Arena benchmarks, MAI-Transcribe-1.5 runs 5x faster with 43-language support, and MAI-Voice-2 clones voices from short audio samples across 15 languages.

WorkInProcess is a free browser-based image studio with AI upscaling and object removal. No uploads, no accounts, everything runs locally.

Microsoft's MAI-Image-2.5 hit No. 3 on Arena. We compare it against Imagen 4 Ultra, GPT-Image-2, FLUX.2 max, and Recraft V3 on five axes that matter for production creative work.

PrismML released Bonsai Image 4B with 1-bit and ternary checkpoints under Apache 2.0. The model retains 95% of FLUX.2 Klein 4B quality at 6.4x smaller size and runs directly on iPhone.

ComfyUI merged native multi-GPU support on May 26, 2026, giving creators with dual or multi-GPU rigs the ability to split image and video generation workloads across all their hardware for the first time.

Microsoft open-sourced Lens, a 3.8-billion-parameter text-to-image diffusion model, on May 25, 2026. It rivals FLUX and SD3, runs in diffusers and ComfyUI, under MIT license.

MooshieUI is a new ComfyUI frontend that replaces the node graph with a clean three-panel interface. It includes one-click install, 13 model family presets including Anima and Illustrious, and built-in tiled upscaling.

A new ComfyUI custom node released May 23, 2026 brings the Untwisting RoPE technique to Z-Image Turbo, enabling training-free style transfer without any model fine-tuning.
NVIDIA Toronto AI Lab open-sources PiD, a plug-in pixel diffusion decoder that replaces VAE in FLUX, SD3, and Z-Image to output 2K-4K in one distilled pass.