
Moonshot AI released Kimi K2.6 on April 20, 2026, a 1-trillion-parameter open-weight Mixture-of-Experts model that scores 58.6 on SWE-Bench Pro, placing first above GPT-5.4 (57.7) and Claude Opus 4.6 (53.4). The weights are public on HuggingFace under a modified MIT license. The model runs 300 simultaneous sub-agents across 4,000+ coordinated tool calls, supports a 256K context window, and handles text, images, and video natively. For developers and creators building agentic workflows, this is the most capable open-weight model released to date.
For the broader landscape, see our complete guide to AI coding tools in 2026.
Architecture: What Makes a 1T MoE Model Work

Kimi K2.6 is a Mixture-of-Experts model, which means not all 1 trillion parameters are active at once. Each token activates only 32 billion parameters: 8 selected from a pool of 384 experts per layer, plus 1 shared expert. The model has 61 layers in total, including one dense layer. This architecture delivers near-frontier capability at a fraction of the inference cost of a dense 1T model.
Attention is handled by Multi-head Latent Attention (MLA), a technique first introduced in DeepSeek's architecture that compresses the key-value cache into a low-dimensional latent space. The practical result: significantly lower memory usage during inference, which directly affects how large a context window you can run on a given amount of VRAM. At 256K tokens, Kimi K2.6's context window is one of the longest available in an open-weight model at this scale.
The vocabulary is 160,000 tokens, roughly twice the size of most current models, which improves tokenization efficiency across non-English languages, code, and technical content. Vision is handled by MoonViT, a 400M-parameter encoder that processes images and video frames natively alongside text, without requiring a separate pipeline.
Supported inference engines are vLLM, SGLang, and KTransformers. Running the full model requires high-end server hardware (A100 or H100 class). Quantized versions are emerging from the community on HuggingFace for consumer GPU use cases.
Benchmark Results: First Place Across Coding and Reasoning
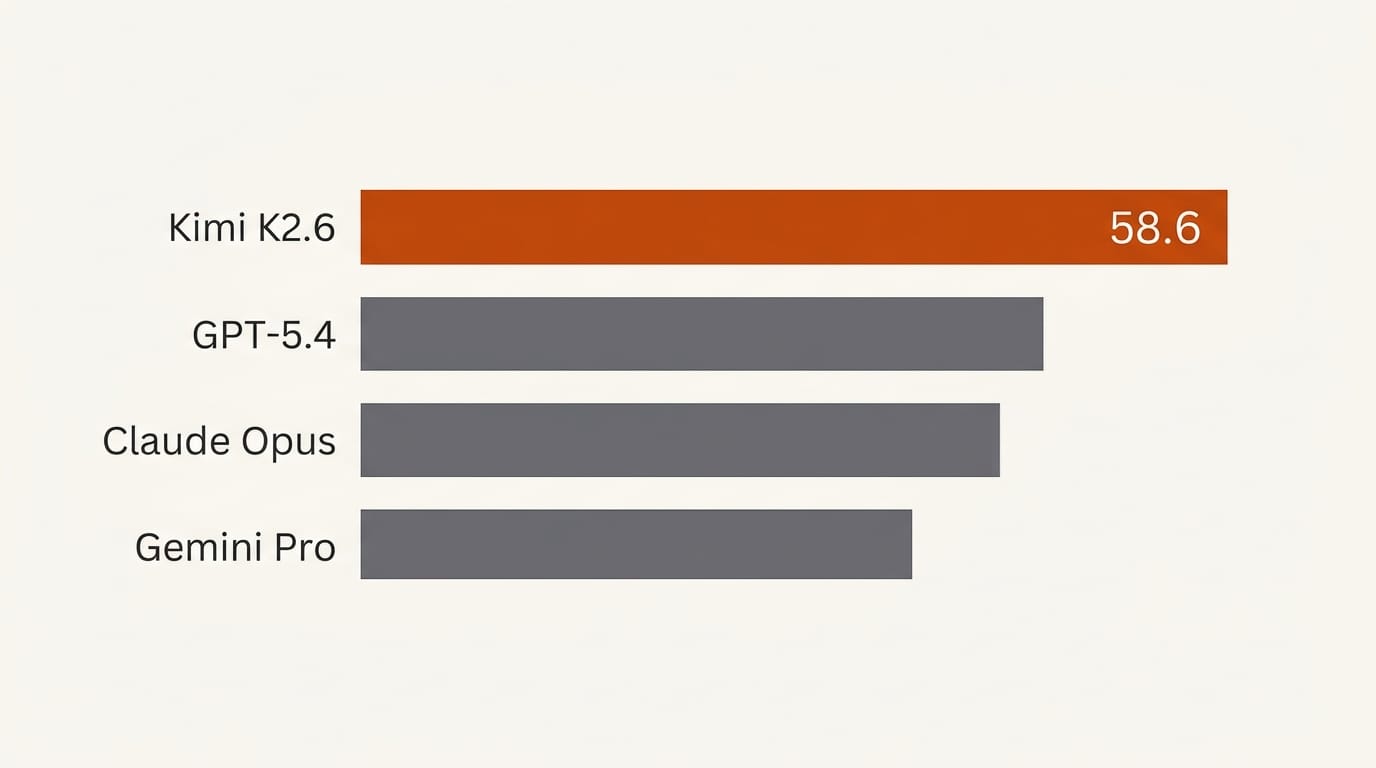
The headline number is SWE-Bench Pro: 58.6. This benchmark measures end-to-end resolution of real GitHub issues: no scaffolding, no hints, no guided test setup. It is the most direct public measure of how useful a model is for actual software development work.
| Benchmark | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | -- |
| SWE-Bench Verified | 80.2 | -- | -- | -- |
| SWE-Bench Multilingual | 76.7 | -- | -- | 76.9 |
| DeepSearchQA | 92.5 | -- | 91.3 | -- |
| Humanity's Last Exam (tools) | 54.0 | -- | 53.0 | -- |
| Toolathlon | 50.0 | -- | 47.2 | -- |
| BrowseComp | 83.2 | -- | -- | -- |
The pattern across benchmarks is consistent: Kimi K2.6 leads on tasks that require multi-step tool use, web research, and long-horizon code execution. These are the same capabilities that determine whether a model is useful inside an agentic pipeline versus a single-turn chat session. SWE-Bench Multilingual is the one benchmark where it trails Gemini 3.1 Pro (76.7 vs 76.9), though the gap is within rounding margin.
Humanity's Last Exam, one of the hardest knowledge benchmarks currently available, shows 54.0 with tools enabled, edging out Claude Opus 4.6 at 53.0. This confirms the model's strength extends beyond code into general reasoning under hard constraints.
Agentic Scale: 300 Sub-Agents, 4,000 Tool Calls
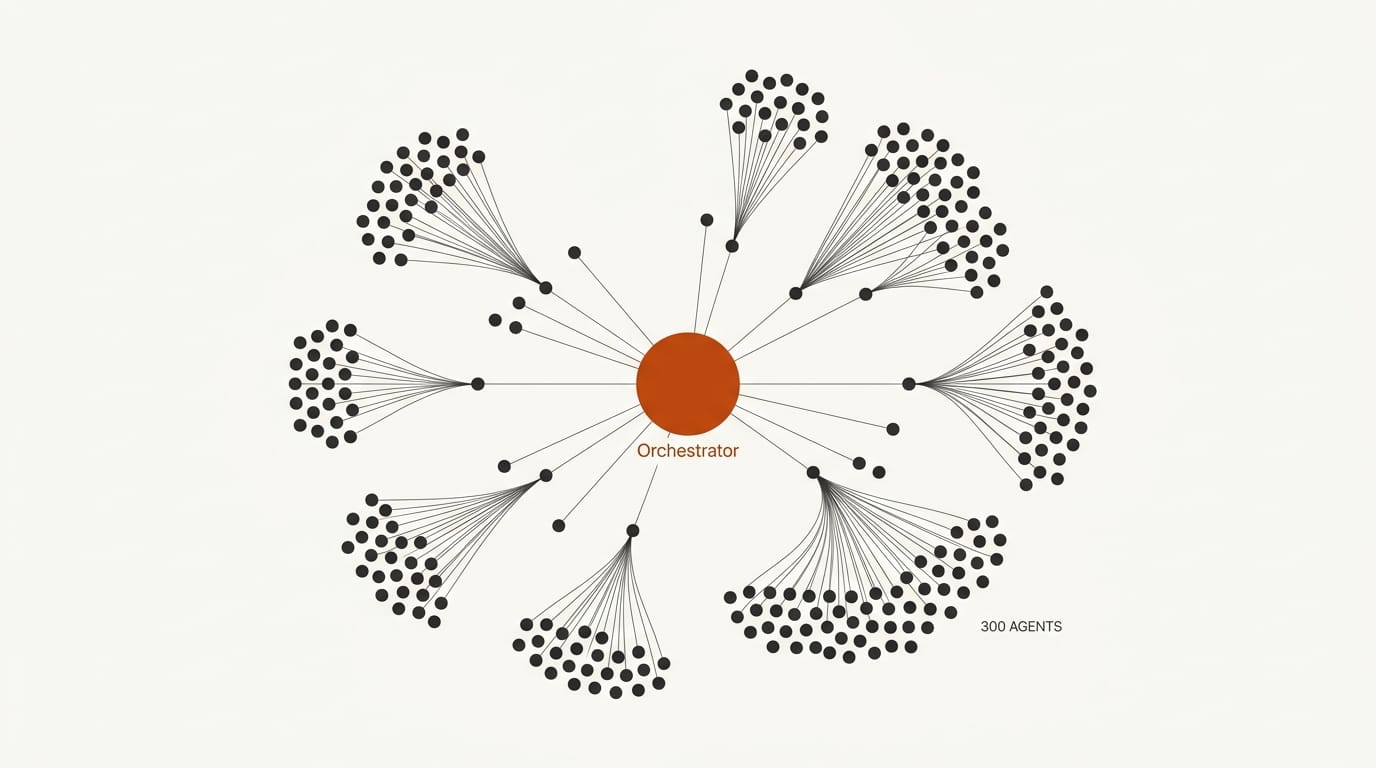
Kimi K2.5 supported 100 parallel sub-agents with up to 1,500 coordinated steps. K2.6 triples the agent count to 300 and nearly triples the step budget to 4,000+ tool calls, with documented runs of 12+ continuous hours of autonomous operation.
This is not just a spec increase: it changes what classes of problems are solvable. A 300-agent system can parallelize an entire engineering project: one group of agents handles research, another handles code generation, a third runs tests, a fourth monitors for regressions. The coordination overhead that made large agent systems impractical is what K2.6's architecture is specifically designed to absorb.
Moonshot AI is previewing "Claw Groups" as a research feature: heterogeneous agent networks where different agent types with different specializations operate within the same task graph. This is distinct from homogeneous swarms where every agent runs the same model. The details of Claw Groups are not fully documented yet, but the framing suggests Moonshot is building toward multi-model orchestration where K2.6 serves as a coordinator directing smaller specialist models.
The --non-interactive flag in the API enables fully automated pipeline use without user prompts between steps. Combined with the long-horizon execution capability, this makes K2.6 viable for overnight batch jobs that would otherwise require human checkpoints.
Open Weights: What the License Actually Allows

The modified MIT license has a single commercial use restriction: if your product exceeds 100 million monthly active users OR generates more than $20 million in monthly revenue, you must visibly credit "Kimi K2.6" in the product interface. Below those thresholds, the license is effectively standard MIT: you can run it, fine-tune it, build commercial products on it, and distribute derivatives without restriction.
For context, 100 million MAU is larger than most SaaS companies ever reach. $20 million monthly revenue is $240 million ARR. For the overwhelming majority of startups, agencies, and enterprise teams, K2.6 is commercially free. The credit requirement at scale is mild compared to what closed-model API costs would be at equivalent usage levels.
The weights on HuggingFace are the canonical source. Community quantizations (GGUF, AWQ, GPTQ variants) are already appearing, which will make the model accessible on consumer hardware for teams that want to self-host without data center infrastructure.
How to Access It
Three options depending on your setup:
- API: $0.60 per million input tokens, $2.50 per million output tokens via Moonshot's platform. Competitive with other frontier-tier APIs, and significantly cheaper than Claude Opus 4.6 or GPT-5.4 for the same performance tier on coding tasks.
- Self-hosted: Full weights on HuggingFace via vLLM or SGLang. Requires server-grade GPU hardware for the full model. KTransformers enables CPU-offloaded inference for research use.
- Web interface: kimi.com provides access to the model and agent mode without any setup. Useful for evaluating the model before committing to API integration.
For teams currently paying for closed frontier APIs to handle coding and agentic tasks, K2.6 is worth a direct benchmark comparison on your actual workload. The SWE-Bench numbers suggest parity or better on code-heavy pipelines, at API pricing that is meaningfully lower for high-volume use cases.


