GitHub Copilot now routes each task to the best available model automatically and caches repeated prompt context, changes the company says can cut token cost by up to 72 percent in aggressive mode. The June 17 announcement details a new routing model plus prompt caching and on-demand tool loading aimed at long agent sessions.
How to Integrate: Turn On Auto and Stop Model-Picking
The practical move is to switch Copilot to Auto and let it choose models per task instead of hand-selecting one. Copilot routes based on which model is healthy right now and what kind of work it is doing, from quick edits to deep reasoning. For long agentic runs, structure your sessions so repeated prompt prefixes stay stable, which lets prompt caching reuse model state instead of reprocessing the same context every turn.
Why It Matters
Token cost is the quiet tax on heavy Copilot use, and most developers leave money on the table by pinning a single premium model for everything. Automatic routing sends simple work to cheaper models and saves the expensive ones for hard problems. GitHub reports its routing held accuracy within four points across 16 language families, so the savings do not come at the price of correctness on non-English codebases.
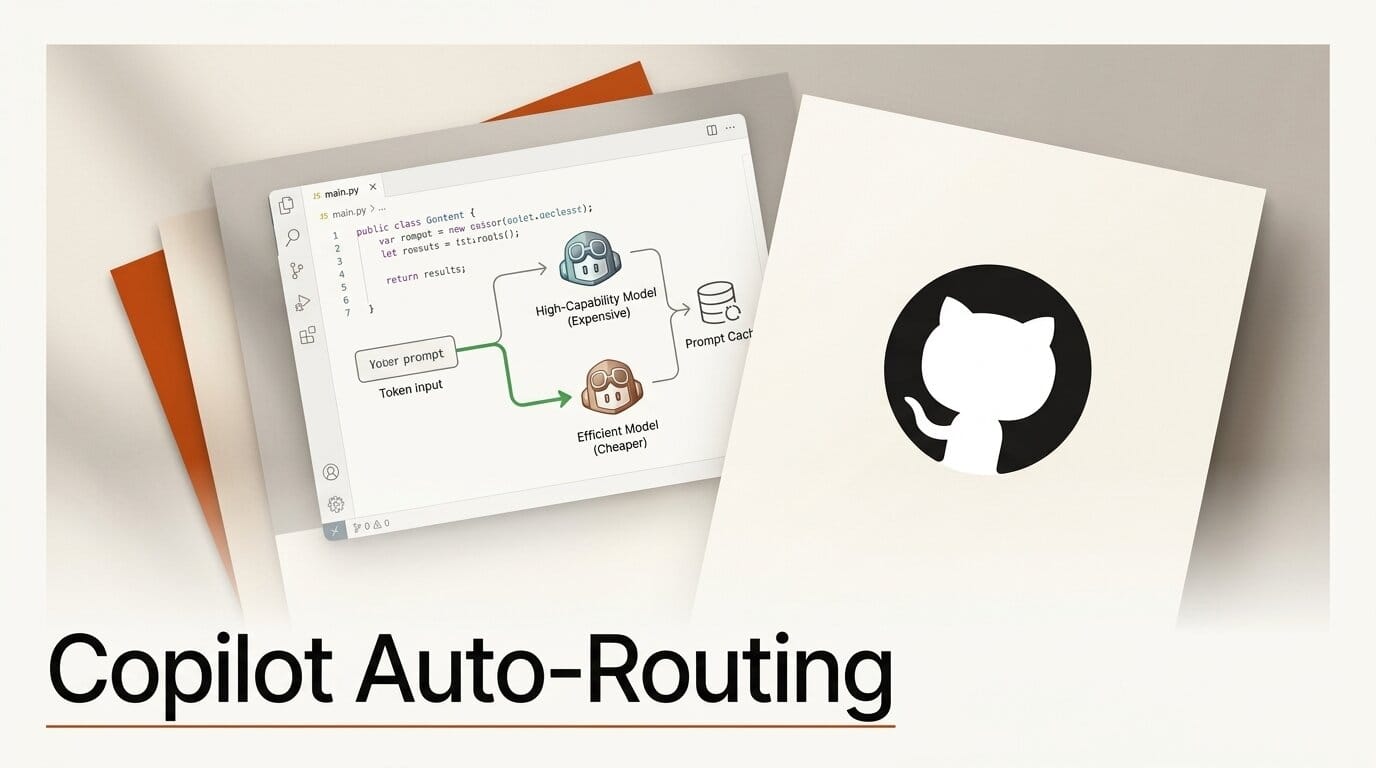
Key Details
Routing: A routing model called HyDRA picks per task; GitHub cites operating points from about 13 percent savings while exceeding Sonnet quality up to roughly 72 percent savings in its aggressive setting, per the auto model selection docs.
Prompt caching: Cache-aware routing avoids switching models at cache boundaries so prefix reuse is preserved.
Deferred tools: Tool definitions load on demand instead of shipping full schemas every turn, shrinking fixed context in big repos. VS Code documented the same gains in its token efficiency post.
What to Do Next
Open Copilot settings, switch model selection to Auto, and run a normal coding session to watch the routing in action. If you also work across editors, our VS Code 1.125 model providers coverage pairs well with this change.


