
Open-weights text-to-speech models have lagged behind commercial APIs in quality for years. Mistral just closed that gap. Voxtral TTS, a 4-billion-parameter open-weights model released March 26, scores higher on naturalness than ElevenLabs Flash v2.5 in human evaluations and matches ElevenLabs v3 quality. It clones any voice from three seconds of audio, supports nine languages, and runs at 70ms latency. The weights are free. For creators and developers who have been locked into proprietary voice APIs, this is the first credible open alternative.
Background
Mistral AI has built its reputation on open-weights language models. Mistral Small 4 shipped a 119B multimodal model. Mistral Forge lets enterprises build custom models. But speech generation was a gap in their lineup, one dominated by ElevenLabs, Deepgram, and OpenAI, all of which keep their model weights proprietary.
Voxtral TTS is Mistral's first entry into speech, built on the Ministral 3B backbone. The architecture combines a 3.4B transformer decoder, a 390M flow-matching acoustic transformer, and a 300M neural audio codec into a single pipeline. The full weights are available on Hugging Face under CC BY-NC 4.0, with API access at $0.016 per 1,000 characters through Mistral's platform.
Deep Analysis
Benchmark Performance Changes the Open-Source Calculus
The headline numbers are strong. In human evaluations, Voxtral TTS achieved a 62.8% listener preference rate against ElevenLabs Flash v2.5 on flagship voices and a 69.9% preference rate in voice customization tasks. It matches ElevenLabs v3, the premium tier, on emotional expressiveness while maintaining latency comparable to the much faster Flash model.
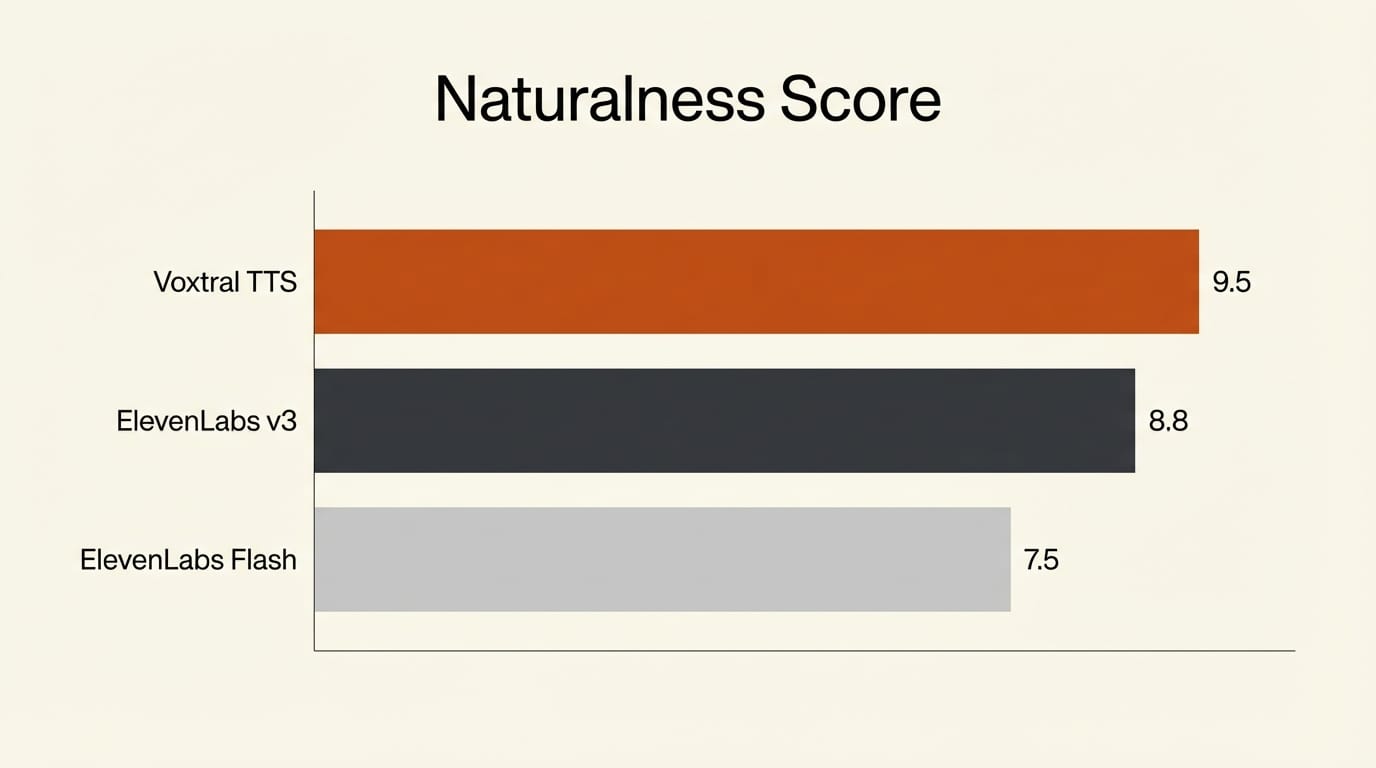
Previous open-weights TTS models like Fish Audio S2 and Hume TADA have made progress, but neither claimed parity with ElevenLabs' premium tier. Voxtral is the first open model to do so credibly, backed by human evaluation data rather than automated metrics alone.
Three-Second Voice Cloning at Enterprise Scale
Voxtral's voice cloning needs just three seconds of reference audio to capture a speaker's rhythm, pauses, and emotional expression. The model also handles cross-lingual adaptation natively: a French voice prompt speaking English retains natural French intonation. For creators building multilingual content, that removes a production step that previously required separate recording sessions or manual tuning.
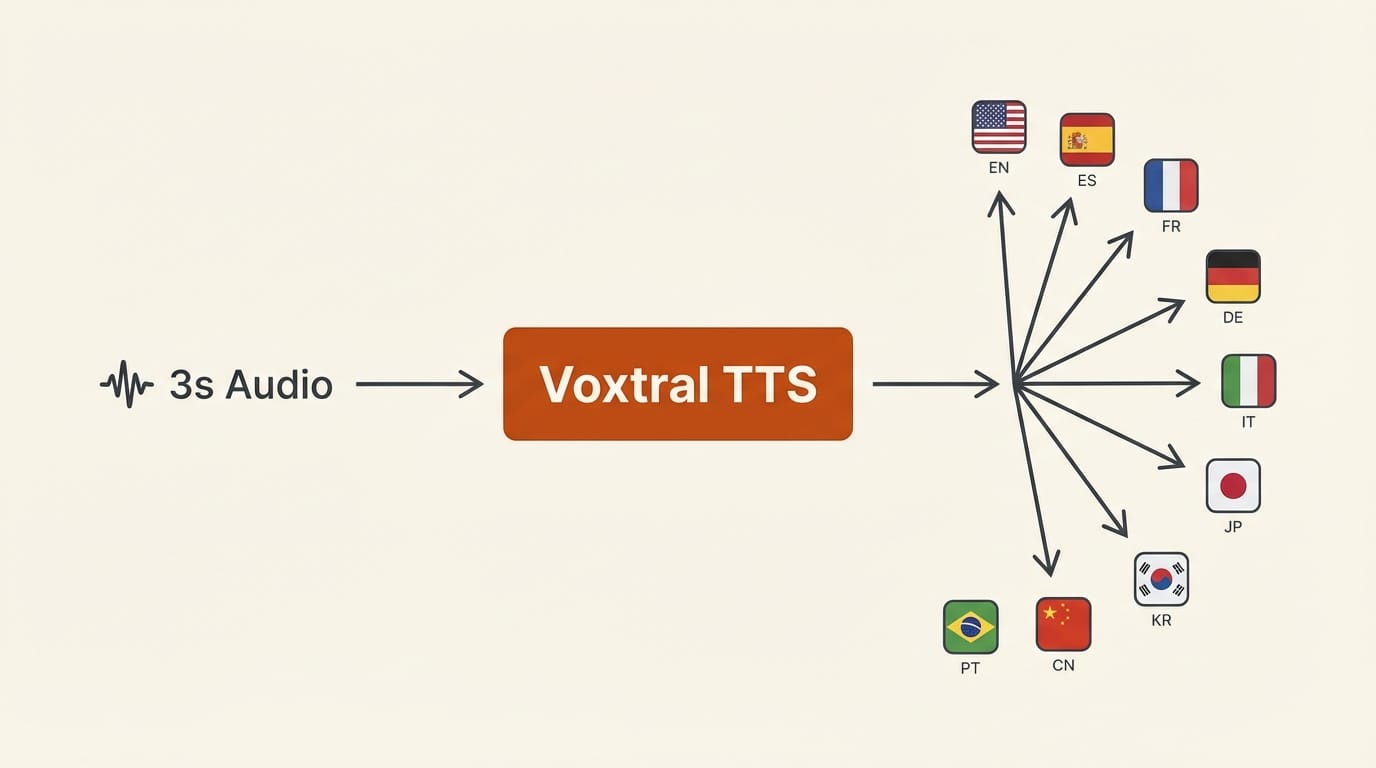
The nine supported languages are English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic. The real-time factor of 9.7x means Voxtral generates audio nearly 10 times faster than playback speed, with a time-to-first-audio of 70ms for typical inputs. Natively, it generates up to two minutes per call, with the API handling longer content via smart interleaving.
The Self-Hosting Advantage
The most significant implication of open weights is data sovereignty. Enterprises can download Voxtral TTS, run it on their own servers, and never send a single audio frame to a third party. For healthcare, legal, and financial services companies that cannot send voice data to external APIs, this removes the primary blocker to adopting AI-generated speech.
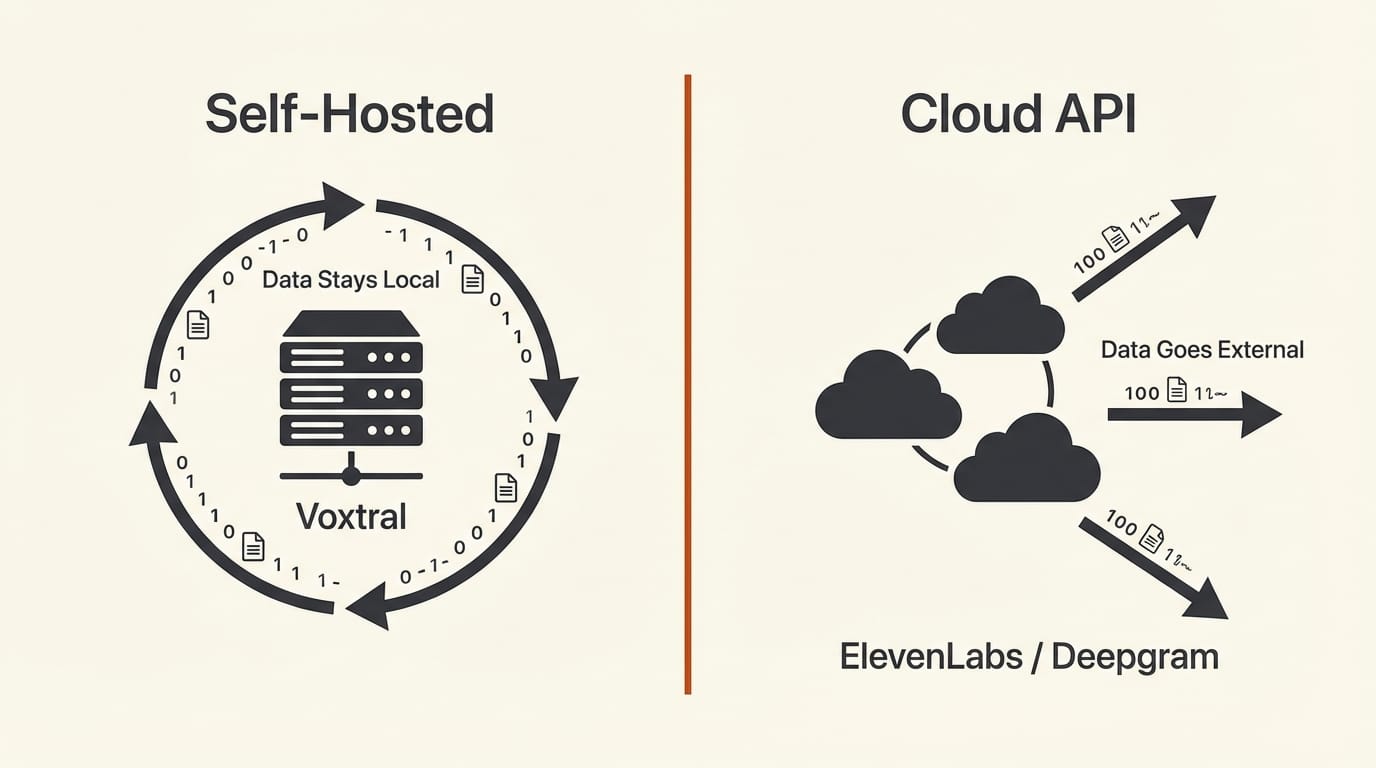
At $0.016 per 1,000 characters via the API, Voxtral is already cheaper than ElevenLabs. But self-hosting eliminates per-character costs entirely, replacing them with fixed infrastructure costs. For high-volume use cases like voice agents, IVR systems, and content narration at scale, the economics shift dramatically. Mistral's VP of science operations noted the cost is "a fraction of anything else on the market."
Where Voxtral Fits in the Voice AI Market
The global voice AI market crossed $22 billion in 2026, with the voice agent segment projected to reach $47.5 billion by 2034. ElevenLabs recently announced a partnership with IBM to bring premium voice capabilities into watsonx. Deepgram, OpenAI, and Google all offer proprietary voice APIs.
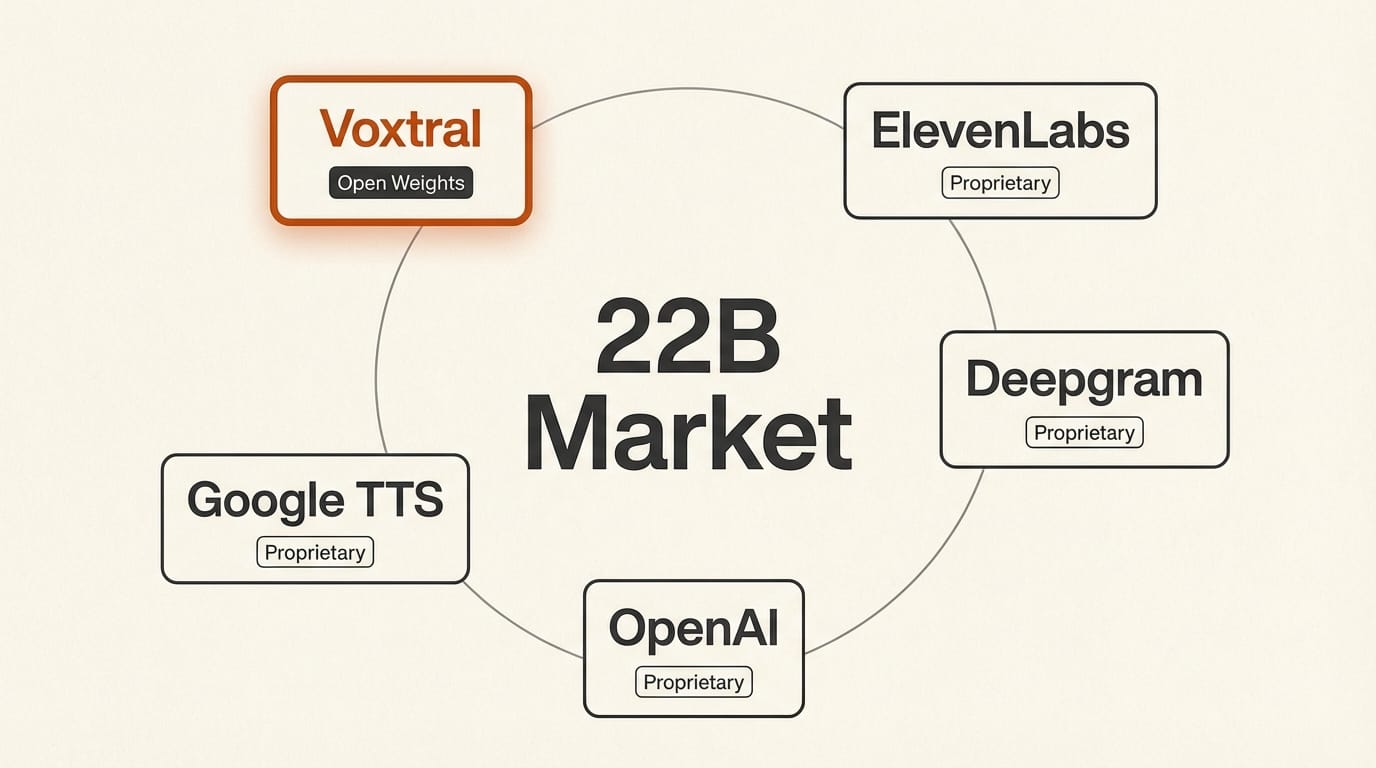
Voxtral's open-weights approach is a direct challenge to this proprietary stack. All generated audio includes SynthID watermarks, addressing the safety concern that open models could enable voice fraud. The CC BY-NC 4.0 license means commercial use requires Mistral's API or a separate agreement, a pragmatic middle ground between fully open and fully closed.
Impact on Creators
For creators doing voiceover, narration, or podcast production, Voxtral offers a way to test frontier-quality TTS without committing to an ElevenLabs subscription. The three-second voice cloning makes it fast to evaluate on real content. Pair it with Mistral Small 4 for text generation and you have a text-plus-voice pipeline built entirely on open-weights models.
For developers building voice agents or interactive applications, self-hosting eliminates the latency and cost overhead of external API calls. The 70ms time-to-first-audio and 9.7x real-time factor mean Voxtral can power conversational interfaces without perceptible delay. Teams already using Mistral's language models can now add voice to their stack without introducing a new vendor.
Key Takeaways
1. Voxtral TTS is the first open-weights model to credibly match ElevenLabs' premium tier in human evaluations of naturalness and emotional expressiveness.
2. Three-second voice cloning with cross-lingual adaptation across nine languages removes significant production overhead for multilingual content.
3. Self-hosting eliminates per-character API costs and data sovereignty concerns, making frontier-quality voice AI accessible to regulated industries.
4. The CC BY-NC 4.0 license is a pragmatic middle ground: free for research and personal use, API or agreement required for commercial deployment.
What to Watch
The CC BY-NC 4.0 license is the key limitation. Creators and startups who want to self-host Voxtral commercially will need to negotiate with Mistral, and those terms are not yet public. Watch for whether the community fine-tunes Voxtral for specialized domains like audiobook narration, gaming dialogue, or accessibility. If the model proves as customizable as Mistral's language models, it could fragment ElevenLabs' market share in the same way open LLMs have pressured proprietary API providers. The voice AI market just got its first real open-weights contender.
Deep dive by Creative AI News.
Subscribe for free to get the weekly digest every Tuesday.


