For years, the most powerful AI creative tools lived in the cloud. You uploaded your prompts, waited for a remote GPU cluster to process them, and downloaded the results. GDC 2026 (March 9-13) signaled a decisive shift in the opposite direction. Across five days at the Moscone Center in San Francisco, NVIDIA, AMD, Tripo, and ComfyUI collectively demonstrated that production-grade AI generation now runs on the hardware sitting under your desk.
The announcements spanned video generation, 3D asset creation, real-time rendering, and image synthesis. The common thread across all of them: fewer cloud dependencies, faster local inference, and dramatically lower VRAM requirements. For creators, this changes the economics and the workflow of AI-powered production.
Background: The Cloud-to-Local Migration
The shift from cloud-based AI to local execution has been building since late 2025. Open-weight models like Stable Diffusion, Flux, and LTX-Video proved that consumer GPUs could handle meaningful generative workloads. But the experience was rough: high VRAM requirements locked out most users, performance lagged far behind cloud services, and setup demanded command-line expertise.
GDC 2026 addressed all three barriers simultaneously. NVIDIA slashed VRAM requirements by up to 60% with new quantization formats. AMD made its ROCm compute stack work with ComfyUI out of the box on Windows. Tripo demonstrated 3D asset generation in two seconds. And ComfyUI launched an App View that hides node graphs behind a clean interface. Each announcement individually would be significant. Together, they represent a platform shift.
Deep Analysis
NVIDIA DLSS 4.5: AI Frame Generation Gets Smart
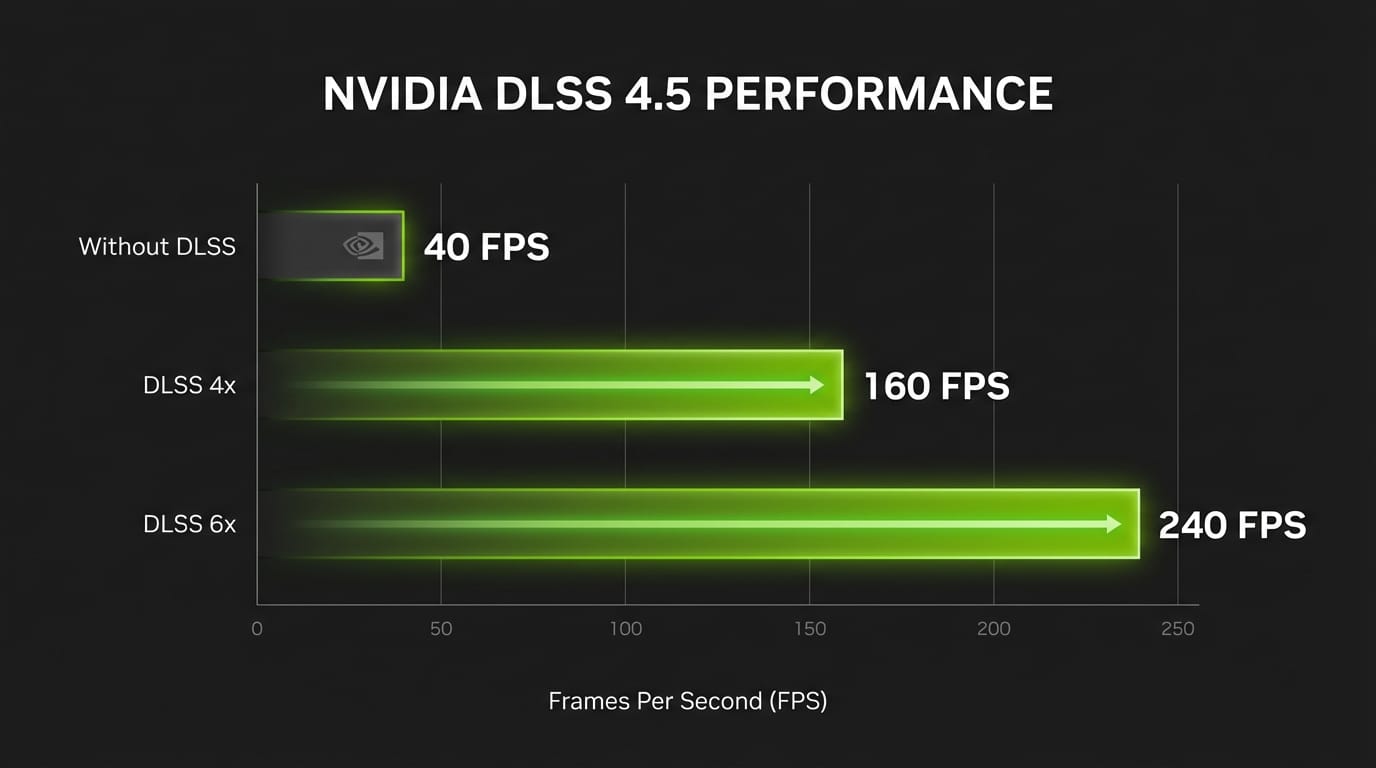
NVIDIA's DLSS 4.5 announcement introduced Dynamic Multi Frame Generation, a system that intelligently adjusts how many AI-generated frames it inserts during gameplay. Rather than running at a fixed 2x or 4x multiplier, the new mode shifts between 2x, 4x, and 6x generation in real time based on scene complexity and the display's refresh rate.
The goal is practical: hold a smooth output at whatever refresh rate your monitor supports, whether that is 120Hz, 144Hz, or 240Hz, by generating only the extra frames needed. In a live GDC demo, NVIDIA showed seamless transitions between multipliers as a camera moved from a simple ship cockpit to a dense interior scene. The system scaled from 2x to 6x frame generation without visible artifacts.
The 6x mode, which generates five AI frames for every traditionally rendered frame, pushes 4K path-traced gaming past 240 FPS on an RTX 5090. Alan Wake 2 gained a 5-20% FPS boost alongside approximately 300 MB of VRAM savings through the related RTX Mega Geometry technology, which compresses geometry into clusters and updates them up to 100x faster than previous methods.
For creators working in real-time engines, the implications extend beyond gaming. Path-traced viewport rendering in Unreal Engine and Unity becomes viable for rapid iteration when DLSS 4.5 can sustain interactive frame rates on scenes that would otherwise run at single-digit FPS. NVIDIA's broader GTC 2026 AI roadmap confirms this is part of a deliberate strategy to make path tracing the default rendering approach.
DLSS 4.5 Dynamic Multi Frame Generation and the 6x mode launch March 31 through the NVIDIA app beta, requiring GeForce RTX 50 Series hardware and driver 595.79 or newer. Twenty games have announced native DLSS 4.5 integration, including 007 First Light, CONTROL Resonant, and Tides of Annihilation.
NVIDIA and ComfyUI: Local Video Generation Hits 4K

The NVIDIA and ComfyUI collaboration announced at GDC targets the biggest friction point in local AI video generation: it was slow, memory-hungry, and required expert-level setup. Three specific improvements change the calculus.
First, NVIDIA's NVFP4 quantization format delivers 2.5x faster inference and 60% lower VRAM usage on RTX 50 Series GPUs. The FP8 format, available on RTX 40 Series cards, provides 1.7x faster performance with 40% VRAM reduction. In practical terms, a GeForce RTX 5090 with 32GB of VRAM can generate a 720p, 24fps, 4-second clip entirely in GPU memory in about 25 seconds. That same workload would have required cloud processing six months ago.
Second, RTX Video Super Resolution is now available as a ComfyUI node, delivering 4K upscaling that runs 30x faster than alternative local upscalers. The upscaler runs on RTX Tensor Cores in real time, sharpening edges and removing compression artifacts. This means creators can generate at 720p for speed, then upscale to 4K for final output, all locally.
Third, ComfyUI's new App View provides a simplified interface that hides the node graph behind standard UI controls. This is the piece that makes local AI video generation viable for creators who are not programmers. NVFP4 and FP8 model variants are available for LTX-2.3, FLUX.2 Klein 4B, and FLUX.2 Klein 9B directly within the app. Our earlier coverage of the NVIDIA-ComfyUI partnership details the full workflow for getting started.
AMD ROCm 7.2: Breaking the NVIDIA Lock-In

AMD's ROCm compute stack has been the perpetual "almost there" of local AI. It worked on Linux, sometimes, with specific GPU models, if you were willing to debug driver issues. ROCm 7.2 changes the story in a meaningful way.
The headline: official ROCm support is now built into ComfyUI Desktop v0.7.0 on Windows. That means AMD Radeon GPU owners can run Stable Diffusion, Flux, and other generative models through ComfyUI without manual driver configuration, environment variable juggling, or Linux-only workarounds. It installs and runs.
Performance numbers back up the claim that AMD hardware is now competitive for creative AI workloads. AMD reports a 5x overall uplift for ComfyUI workflows, with model-specific gains of 2.6x faster SDXL and 5.2x faster Flux S on Ryzen AI Max systems. The WAN 14B model sees a 5.4x boost on Radeon AI PRO R9700 GPUs.
The broader significance is that ROCm 7.2 is now a unified Windows and Linux release, a departure from AMD's historically Linux-only approach. It supports Ryzen AI 400 series APUs, meaning even laptop users with integrated AMD silicon can run local AI inference. The integration with Adrenalin 26.1.1 drivers means the AI compute stack installs alongside standard GPU drivers rather than requiring a separate setup.
For the creative AI ecosystem, AMD entering the consumer AI race with working software is a competitive pressure that benefits everyone. More hardware options mean lower prices, and AMD's open-source approach to ROCm gives developers flexibility that CUDA does not.
Tripo P1.0: Production 3D in Two Seconds

Tripo's P1.0 announcement at GDC tackled the most persistent problem in AI 3D generation: the output looks impressive but is unusable in production. AI-generated meshes typically have chaotic topology, broken normals, and geometry that crashes real-time engines. Artists spend more time repairing AI output than they would have spent building the asset manually.
P1.0 uses a native 3D diffusion architecture that generates directly in three-dimensional space using a unified probabilistic approach. Instead of predicting geometry sequentially, it resolves the global structure of a 3D object holistically. The result, visible in wireframe view, shows organized edge loops, even polygon distribution, and clean silhouettes that resemble hand-built topology rather than typical AI output.
The generation speed is two seconds for a production-ready low-poly mesh. That includes clean topology suitable for real-time pipelines, game engines, XR applications, and web 3D. The P1.0 model currently generates geometry without textures; texture generation is a separate step. Alongside P1.0, Tripo also showed H3.1, a high-fidelity flagship model designed for maximum visual accuracy.
Smart Mesh workflows, prompt-based and reference-based generation, and real-time iteration within Unity and Unreal Engine were demonstrated live at Booth 1141. Tripo positions P1.0 as the beginning of what they call "AI 3D 2.0," where the focus shifts from generating impressive demos to producing assets that ship in actual products.
Impact on Creators
The collective message from GDC 2026 is that creative AI is becoming a local-first discipline. The practical implications break down into three categories.
Cost reduction. Cloud AI video generation typically costs $0.05 to $0.50 per clip depending on length and resolution. At 50 iterations per concept, that is $2.50 to $25.00 per final asset. Local generation on hardware you already own reduces the marginal cost to electricity. For studios producing hundreds of concept videos per project, the savings compound quickly.
Speed and iteration. Round-trip latency to cloud services, including upload, queue time, processing, and download, typically runs 30 seconds to several minutes. Local generation on an RTX 5090 produces a 4-second video clip in 25 seconds with no network dependency. When creative work depends on rapid iteration, cutting latency from minutes to seconds changes what is possible in a single session.
Privacy and ownership. Local inference means your prompts, reference images, and generated outputs never leave your machine. For studios working under NDA on unannounced projects, this eliminates a category of risk that cloud APIs introduce.
Key Takeaways
- DLSS 4.5 Dynamic Multi Frame Generation launches March 31 with intelligent frame scaling up to 6x, enabling 4K path-traced gaming above 240 FPS on RTX 50 Series.
- NVIDIA NVFP4 quantization delivers 2.5x faster video generation and 60% lower VRAM on RTX 50 Series GPUs. RTX Video Super Resolution upscales to 4K 30x faster than alternatives.
- AMD ROCm 7.2 ships as a unified Windows/Linux release with native ComfyUI integration, delivering up to 5.2x faster Flux inference on Ryzen AI Max.
- Tripo P1.0 generates production-grade 3D meshes with clean topology in two seconds, ready for Unity and Unreal Engine without manual repair.
- ComfyUI App View removes the technical barrier of node-based workflows, making local AI generation accessible to non-programmers.
What to Watch
NVIDIA GTC 2026 (March 16-19). GDC focused on gaming and creative tools. GTC, starting three days later in San Jose, will reveal the broader AI infrastructure roadmap. Expect announcements about next-generation inference hardware and enterprise deployment of the same local AI technologies shown at GDC.
RTX Mega Geometry open-source release. NVIDIA committed to open-sourcing its latest Mega Geometry innovations later this year. This technology, which compresses geometry clusters and updates them 100x faster, could become foundational for real-time 3D applications beyond gaming.
AMD ROCm adoption rates. The software is now available, but ecosystem adoption determines whether AMD becomes a real alternative for creative AI. Watch for third-party model optimization and workflow tool support beyond ComfyUI.
Tripo P1.0 pipeline integrations. Two-second 3D generation is impressive in a demo. The test is whether the output quality holds across diverse asset types and whether the Unity and Unreal Engine plugins mature into reliable production tools.
The hybrid model. Local AI will not replace cloud services entirely. Heavy training jobs, multi-minute video generation, and large-batch processing still benefit from cloud scale. The emerging pattern is a hybrid workflow: iterate locally, scale to cloud. GDC 2026 made the local half of that equation dramatically more capable.